USBメモリのパーティションが統合できないとき(Windows 11)
セキュリティのために、使っていないUSBメモリを(クイックフォーマットではなく)フォーマットをしたいと思い、作業を試みた。
USBメモリをPCに差し込み、
Windowsマークを右クリック→ディスクの管理で、
接続されているディスクを確認することができる。
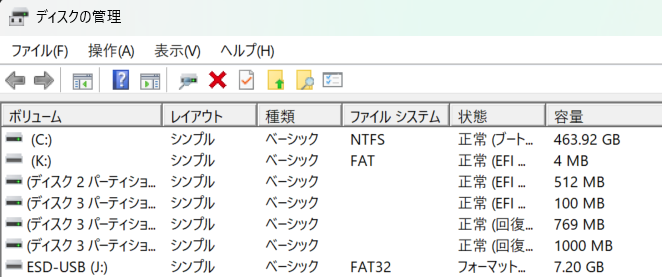
ディスク5には複数のパーティションがある。
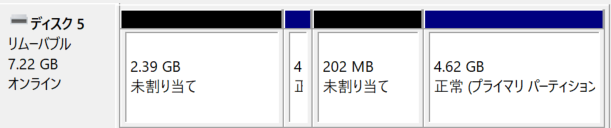
4.62GBのパーティションを右クリックし、ボリュームの削除をクリックしたが、2つの未割り当てパーティションが統合されない。
調べたところ、
・USBメモリをOSのインストールメディアとして使うなどすると、複数のパーティションに分割される
・この状態だと「ディスクの管理」からではパーティションの統合ができない
・コマンドプロンプトから実行可能らしい
Windows11でも実行できたので、その方法を以下に紹介する。
(※間違えて対象以外のディスクを削除すると、保存していたファイルを戻せなくなるため、作業は要注意!)
1)画面下の検索窓から、コマンドプロンプトを実行する。
2)以下コマンドを入力。「許可しますか?」ホップアップが出てくるので「はい」を押す。
diskpart
3)接続されているディスクを以下のコマンドで検索する。ディスク5が対象のUSBメモリである。
list disk
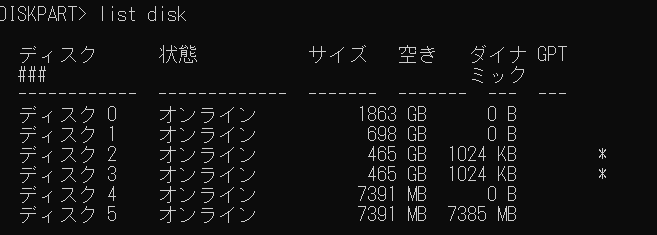
4)ディスク5を選択するため、以下のコマンドを入力する。
select disk 5

5)目的のディスクが選択できたことを確認してから、以下のコマンドでディスク構成情報を全て削除する。少し待つと、パーティションの削除が完了する。
clean

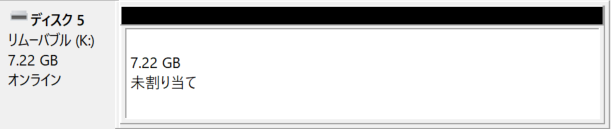
この状態で、新たにフォーマットすれば、USBメモリを再利用できる。
DeepL個人的Tips(画像から読み込み、大量文字のコピー)
あまり知られていないであろう個人的なDeepLアプリの活用テクニックを紹介します。
1)画像のテキスト読み込み
PDFや写真の文字を翻訳したいときに使います(今ではスマホの標準カメラでも同じことができますが、仕事ではPCメインですから)。
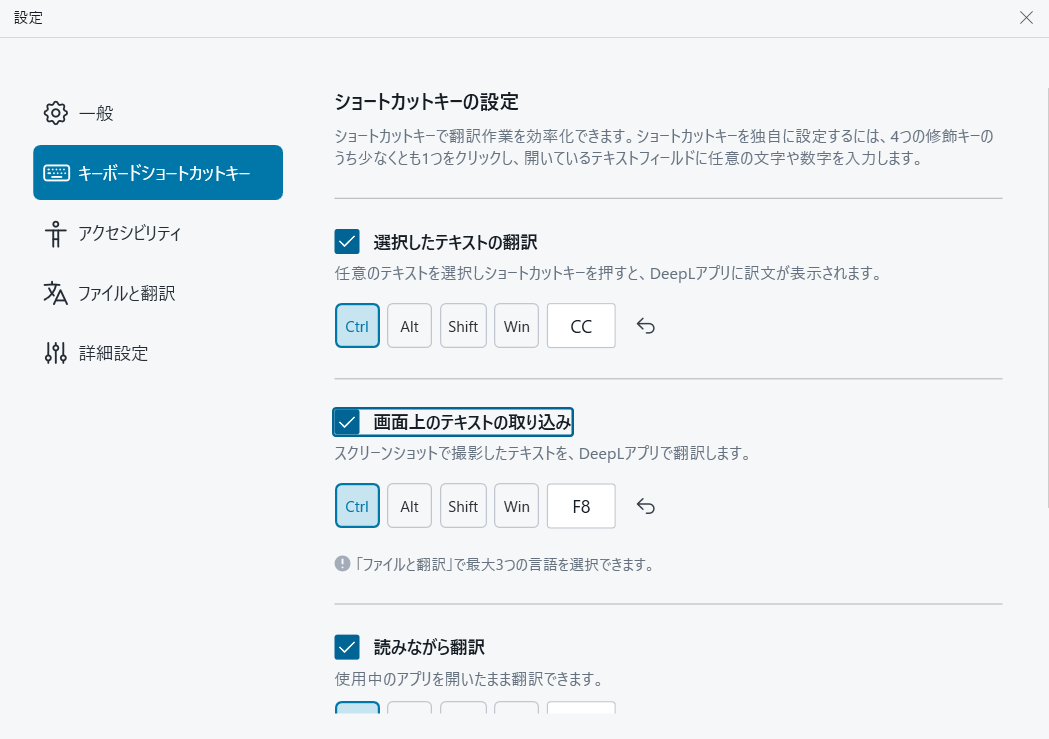
・DeepLのアプリの左上3本線マーク→「設定」→「キーボードショートカットキー」の順に進みます。
・上から2つ目の「画面上のテキストの取り込み」にチェックを入れる
・読みたい画像を開き、ctrl+F8でカーソルが十字になるので、読みたい個所をドラッグする
・DeepLアプリに翻訳結果が表示される
注意点としては、「設定」の「ファイルと翻訳」で日本語にチェックを入れていないと、日本語として読み取ってくれないことです。また読み取った文章は改行を取り除いてくれないため、自分で手直しする必要があり少し不便です。
2)大量文字列のコピー
DeepLキーボードショートカットのctrl+CCによるコピー&翻訳や、日本語訳された文章をコピーして他のファイルに張り付けることがよくあります。
短い文章だと問題ないですが、数千文字以上のコピーを一度にやろうとすると、クリップボードへのコピーがうまくいかないことがあり困っていました。何度やってもコピーできないので、文章を細切れにしてコピペを何度も反復したことがあります。単調作業で疲れました。
発見した対処法ですが、ctrl+CCやctrl+Cを押したときに数秒長押しすると、正しく機能することが分かりました。
おそらくDeepLアプリを動かすときに一時的にメモリの容量不足になる(?)のではないでしょうか(自宅のスペックの高めPCだと起こらないようでした)。
すぐにキーを離すと処理が追い付かないため、長押しして待つことでクリップボードにコピーされる時間をとると解決しました。
皆さんの効率化につながると幸いです。
【業界説明】環境コンサルとは
環境コンサルティング業界で勤めていますが、この業界は外からは分かりづらいと感じます。一口に環境コンサルと言っても、やっていることがばらばらで、企業研究の際に苦労した覚えがあります。今後、就職や転職でこの業界を考える方のために、私なりの考えを整理してみます。
ここでの情報は1企業で勤めている筆者個人の考えであり、業界全体の共通認識でも、所属企業の見解でもありません。
環境コンサルティング企業とは
環境分野に特化したコンサルティング企業の総称です。分野としては、廃棄物、化学物質、海洋保全、放射線など、様々な環境分野および環境に起因する人の健康問題に関する高い専門性を持っています。主要な顧客は、民間企業や行政の環境部門を担当する部署になります。
環境コンサルティング企業の業務分野
環境コンサルティング業界が取り扱う専門分野は、以下のように多岐にわたります。
- 建築系:エンジニアリング、環境アセスメント
- 化学系:川、海、土壌などの化学物質測定
- 生物系:海や山での生物調査、自然環境調査
- 経営系:ESGやTCFDなど企業の環境対応
これらの分野は複合的に関わっていて、環境分野の複雑さがうかがえます。環境コンサルティング企業には様々な環境分野のバックグラウンドを持った専門家が必要ともいえます。
環境コンサルティング企業の業務内容
環境コンサルティング企業が顧客から受注する具体的な業務には、以下のようなものがあります。
- 現地調査、サンプル採取・計測
- 建設計画に関する調査、計画立案、設計
- 最新知見や海外動向の調査
- 環境に関わる経営戦略策定
- ソフトウェア開発
業務内容も様々ですので、企業ごとに得意な分野が決まっています。現場で測定・分析ができる技術がある企業もあれば、知見調査のみに特化した企業もあります。これが、環境コンサルティング企業を一概にとらえきれない所以でもあります。
環境コンサルティング企業の業種
上記で解説した通り、環境コンサルティング企業はそれぞれ得意分野があります。それは概ね、業種の違いと理解することができます。以下に、関係する業種をまとめました。
- 建設コンサルタント:建物の建設に関わる調査、分析、計画立案、設計などに関する業務を行います。大手建設コンサルティング企業は環境部門を持っており、ここに含まれます。
- 化学系調査会社:環境中の化学物質を測定する技術と知見を持った企業です。水質や土壌成分を調査します。独立系の分析会社が多くあります。
- 生物系調査会社:自然環境の生物を調査します。建設コンサルティング企業が部門として保有している場合もありますし、独立系の企業もあります。
- 環境アセスメント企業:新設時や建設後の環境調査を行う環境アセスメントを行う企業です。電力会社、石油化学や大手重工系企業のグループ企業・子会社に多いです。
- シンクタンク:政策関連の調査に強みをもつ企業です。金融企業が親会社の国内大手シンクタンクが有名です。
- 監査法人:金融領域に強く、ESGや環境経営に関する戦略立案が得意です。国内企業だけでなく、外資系企業も有名です。
環境コンサルタントに求められる資格等
環境コンサルティング企業で専門家として働くには、特に資格等は必要ありません。上記の多彩な業務からわかるように、一律に必要な資格や知見があるわけではありません。ですが、関連する分野の学位・高い専門性は必要で、仕事によっては技術士の資格、英語スキルは求められます。
また余談ですが、環境コンサルティングといっても会社によって業務内容や求められるスキルが異なるため、転職時によく調べる業界全体の情報(学位や職歴、平均年収など)はあまり参考にならないかもしれません。
まとめ
今回は環境コンサルティング企業について情報をまとめてみました。上記のある一分野の人間の意見ですので、興味のある方はぜひご自身で企業情報、転職口コミサイト、公共事業受注実績などを調べてみてください。
Pythonでスペースを含んだフォルダパスを読み込む(Google Colaboratory)
Google Colabでフォルダのパスが通らない事態と解決方法。大した話ではないけども、検索しても引っかからなかったので書きます。
問題のあったフォルダ名
フォルダdrive/MyDrive下に作成された標準名称が「Colab Notebooks」で、スペースが入っています。
事象
まずライブラリをインポートして、Google driveをマウントする。
その後、以下のようなコードを実行。
すると、
/content/drive/MyDrive/Colab
Notebooks/xxxxxx/train.csv
上記のように改行されて認識され、エラーが発生した。
スペースの部分をPython正規表現の「\」「\n」「\s」などに変えて試してみたが、うまくいかなかった。
対応策1
フォルダ名をスペースをハイフンに「Colab_Notebooks」に変えたところ、当然うまくいきました。
対応策2
シングルクォーテーションをダブルクオーテーションに変更すると、うまく認識してくれました。
PythonでもRでも、記号の使い方でパスが正しく通るか変わることがあることは経験がありました。
今回、不思議だったのは、対応策2を一度試して以降、最初のシングルクォーテーションで挟む形式に戻してもパスが通ることです(なのでエラーが出たときのメッセージや画面を貼り付けられず)。
Minicondaインストール手順と最初のライブラリインストール
Acaconda環境から、Minicondaに移行したので、その過程をメモする。
はじめに
Anacondaはデータサイエンスに必要なパッケージが揃っていて、パッケージの依存関係も調整されている。しかし商用利用は有料とのことで、この先どのような利用方法になるかわからないので、Minicondaに移行しようと思う。Minicondaは管理システムcondaが使用できるが、最小限のパッケージの導入で済み、必要なパッケージは自分で追加するという仕組みである。インストール後のサイズがおおよそ、Anacondaで5GBに対し、Minicondaは0.5GB程度で済む。
1.Anacondaをインストールしている場合にはアンインストール
AnacondaとMinicondaは共存させられるみたいだが、紛らわしいので今回はインストール済みのAnacondaはアンインストールした。
2.Minicondaをダウンロード、インストール
Miniconda — miniconda documentation
Windows PCに64bitをダウンロードした。
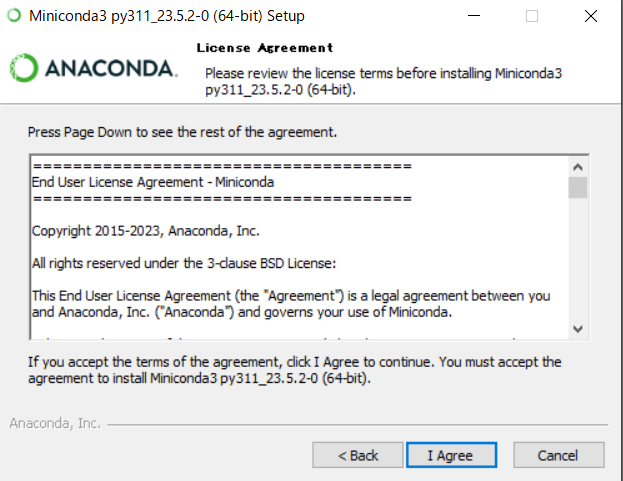
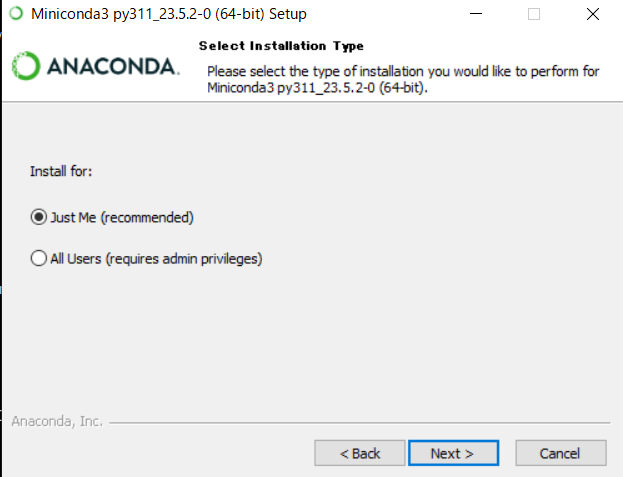
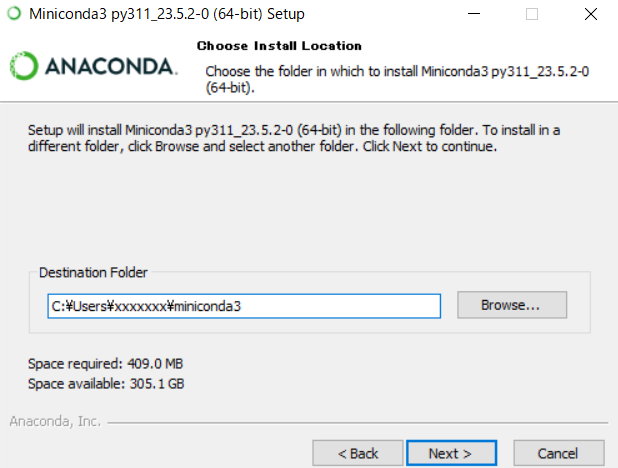
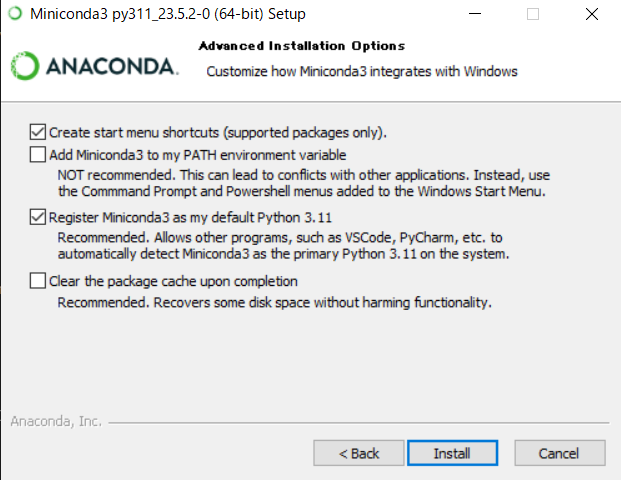
Minicondaのインストールが済んだら、一旦PCを再起動する。次に、必要なパッケージのインストールに進む。
まずはwindowsボタンを押してから、Anaconda promptを起動する。

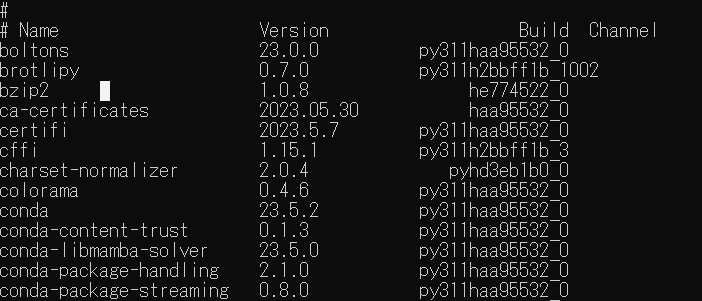
>conda list
>python -V
![]()
>conda -V
![]()
とりあえず、目下使いそうなパッケージをインストールする。
>conda install numpy matplotlib
>conda install jupyter notebook
>conda install notebook ipykernel(これはいらないかも)
Anaconda Prompt上で、以下を打つことでJupyter Notebookが起動できる。
>jupyter notebook
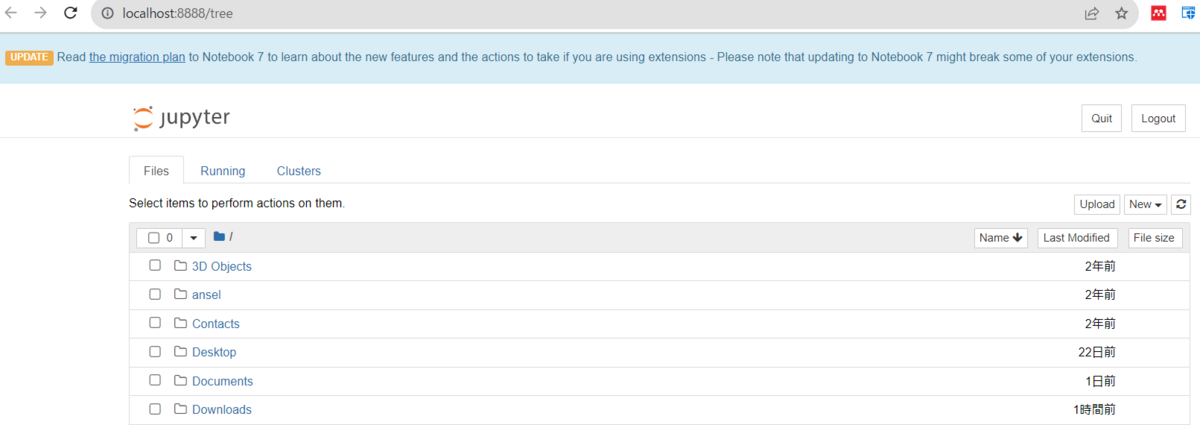
これで最低限のMiniconda環境を整えることができたはず。
Rのcaretパッケージを用いた機械学習テスト
今回は勉強用として、様々な機械学習の手法を用いてみます。
Rのcaretパッケージとは、機械学習の分類・回帰に用いられる様々なパッケージを統合して使いやすくしたパッケージです。今回はデータセットirisを用いて、まずは様々な手法を動かしてみることを目的とします。それぞれのモデルの説明、パラメータチューニングは割愛します(他のブログにお任せします)。
最初にデータセットの外観を確認します。
#アヤメの種類、花弁・がく片
head(iris)
目的変数をSpecies、花弁とがく片の長さと幅を説明変数にする方針とする。
k最近傍法
#k最近傍法
set.seed(123)
irisKNN <- train(
Species ~ .,
data = irisTrain,
method = "knn",
trControl = trainControl(method = "cv")
)
predKNN <- predict(irisKNN, irisTest)
confusionMatrix(data = predKNN, irisTest$Species)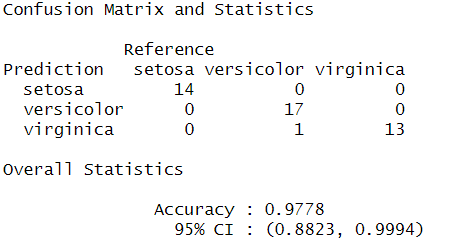
重回帰分析(多項ロジットモデル)
#重回帰分析
set.seed(123)
irisMlt <- train(
Species ~ .,
data = irisTrain,
method = "multinom",
trControl = trainControl(method = "cv")
)
predMlt <- predict(irisMlt, irisTest)
confusionMatrix(data = predMlt, irisTest$Species)
サポートベクターマシン
#SVM
set.seed(123)
irisSVM <- train(
Species ~ .,
data = irisTrain,
method = "svmLinear",
trControl = trainControl(method = "cv")
)
predSVM <- predict(irisSVM, irisTest)
confusionMatrix(data = predSVM, irisTest$Species)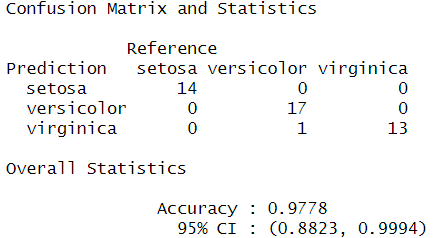
決定木
#決定木
set.seed(123)
irisTree <- train(
Species ~ .,
data = irisTrain,
method = "rpart",
trControl = trainControl(method = "cv")
)
predTree <- predict(irisTree, irisTest)
confusionMatrix(data = predTree, irisTest$Species)
ランダムフォレスト
#ランダムフォレスト
set.seed(123)
irisRF <- train(
Species ~ .,
data = irisTrain,
method = "rf",
trControl = trainControl(method = "cv")
)
predRF <- predict(irisRF, irisTest)
confusionMatrix(data = predRF, irisTest$Species)
ニューラルネットワーク
#ニューラルネットワーク
set.seed(123)
irisNnet <- train(
Species ~ .,
data = irisTrain,
method = "nnet",
trControl = trainControl(method = "cv"),
linout = F
)
predNnet <- predict(irisNnet, irisTest)
confusionMatrix(data = predNnet, irisTest$Species)
勾配ブースティング(線形予測)
#xgboost 線形予測
set.seed(123)
modelXGB <- train(
Species ~ .,
data = irisTrain,
method = "xgbLinear",
trControl = trainControl(method = "cv")
)
predXGB <- predict(modelXGB, irisTest)
confusionMatrix(data = predXGB, irisTest$Species)
まとめ
irisデータはシンプルだった(植物のサイズなので、人間が関わることよりかはばらつきが少なそう)ため、分類結果に差が出ませんでしたね。精度は98%で、決定木以外はクロス集計表の結果も同じとなりました。
今回はデータの正規化、パラメータの検討など全く検討していません。本データを扱う時までに、背景知識目含めて学びなおしたいと思います。