今回は勉強用として、様々な機械学習の手法を用いてみます。
Rのcaretパッケージとは、機械学習の分類・回帰に用いられる様々なパッケージを統合して使いやすくしたパッケージです。今回はデータセットirisを用いて、まずは様々な手法を動かしてみることを目的とします。それぞれのモデルの説明、パラメータチューニングは割愛します(他のブログにお任せします)。
最初にデータセットの外観を確認します。
#アヤメの種類、花弁・がく片
head(iris)
目的変数をSpecies、花弁とがく片の長さと幅を説明変数にする方針とする。
k最近傍法
#k最近傍法
set.seed(123)
irisKNN <- train(
Species ~ .,
data = irisTrain,
method = "knn",
trControl = trainControl(method = "cv")
)
predKNN <- predict(irisKNN, irisTest)
confusionMatrix(data = predKNN, irisTest$Species)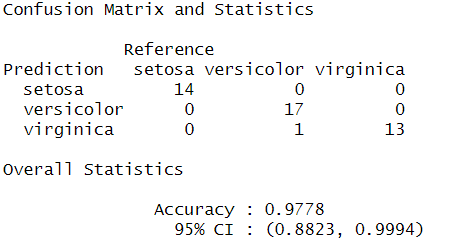
重回帰分析(多項ロジットモデル)
#重回帰分析
set.seed(123)
irisMlt <- train(
Species ~ .,
data = irisTrain,
method = "multinom",
trControl = trainControl(method = "cv")
)
predMlt <- predict(irisMlt, irisTest)
confusionMatrix(data = predMlt, irisTest$Species)
サポートベクターマシン
#SVM
set.seed(123)
irisSVM <- train(
Species ~ .,
data = irisTrain,
method = "svmLinear",
trControl = trainControl(method = "cv")
)
predSVM <- predict(irisSVM, irisTest)
confusionMatrix(data = predSVM, irisTest$Species)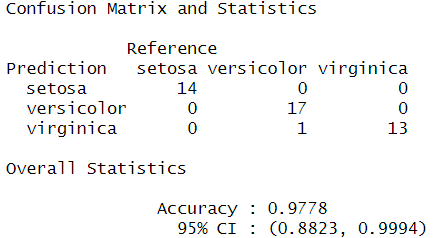
決定木
#決定木
set.seed(123)
irisTree <- train(
Species ~ .,
data = irisTrain,
method = "rpart",
trControl = trainControl(method = "cv")
)
predTree <- predict(irisTree, irisTest)
confusionMatrix(data = predTree, irisTest$Species)
ランダムフォレスト
#ランダムフォレスト
set.seed(123)
irisRF <- train(
Species ~ .,
data = irisTrain,
method = "rf",
trControl = trainControl(method = "cv")
)
predRF <- predict(irisRF, irisTest)
confusionMatrix(data = predRF, irisTest$Species)
ニューラルネットワーク
#ニューラルネットワーク
set.seed(123)
irisNnet <- train(
Species ~ .,
data = irisTrain,
method = "nnet",
trControl = trainControl(method = "cv"),
linout = F
)
predNnet <- predict(irisNnet, irisTest)
confusionMatrix(data = predNnet, irisTest$Species)
勾配ブースティング(線形予測)
#xgboost 線形予測
set.seed(123)
modelXGB <- train(
Species ~ .,
data = irisTrain,
method = "xgbLinear",
trControl = trainControl(method = "cv")
)
predXGB <- predict(modelXGB, irisTest)
confusionMatrix(data = predXGB, irisTest$Species)
まとめ
irisデータはシンプルだった(植物のサイズなので、人間が関わることよりかはばらつきが少なそう)ため、分類結果に差が出ませんでしたね。精度は98%で、決定木以外はクロス集計表の結果も同じとなりました。
今回はデータの正規化、パラメータの検討など全く検討していません。本データを扱う時までに、背景知識目含めて学びなおしたいと思います。